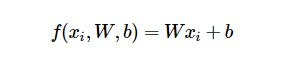As many have reported all over the web, AI can generate words and sentences, not necessarily meaningful or grammatical but we have models that understand linguistic structure. We can generate clickbait, semi-scientific papers, alternative Harry Potter fan fiction. I conducted one of these experiments, and of course it had to involve history. What better way than re-imagine the life of dead legends. I accidentally stumbled on Benjamin Franklin's autobiography when I was perusing Project Gutenberg. Turns out Benjamin was such a fascinating character I'm surprised we don't have a movie about him yet.
1) Data cleanup: removing stop words, punctuation,words that need not be learnt etc.
2) Word/Char representation: Words have to represented in numbers so that mathematical operations can be performed. The unit of representation can be a word or a char. The are kinds of representations: fixed and distributed word representations.
3) Model training. There are three popular models for Natural Language Generation, these are: RNN, LSTM and GRUs. Unlike Feed Forward Neural Networks, these models have loops and are trained with a sequential data with the objective of generating correct sequences.
where f(H) is a tanh function and f(O) is a softmax function.
These networks can be stacked to make Deep RNN as shown below.
Karpathy's blogpost gives a good testimony on how effective they can be.
where X => point wise multiplication ,
Essentially the sigmoid layers are gates. The sigmoid function outputs a value between 0 and 1.
By point-wise multiplying with respective input they decide how much of a multiplicand is propagated. 0 means propagate nothing and 1 means propagate everything. These gates input x(t) and h(t-1) but their weights will differ. C(t)_bar can be thought as the current cell state derived from current input x(t) and previous output h(t-1). The gates i(t) and f(t) will determine how much C(t)_bar and C(t-1) respectively will be propagated to C(t).
Similar to RNNs, the current output h(t) is a function of tanh of current state C(t). The tanh output is gated by sigmoid gate o(t). Christopher Olah's blogpost also does a good job at deciphering these networks.
At the cost of number of trainable weights, LSTMs solve the problem of long term dependencies. There are many variants of LSTMs, a popular one is the Gated Recurrent Unit (GRU) described below.
The GRU is similar to RNN because the cell state is stored in one variable h(t) which is also the cell output; it is a variant of LSTM due to the presence of sigmoid gates z(t) and r(t). Similar to C(t)_bar above h(t)_bar can be thought as the current cell state derived from current input x(t) and h(t-1). r(t) gates how much h(t-1) propagates to h(t)_bar, it is also known as a reset gate because it allows the network to forget past information h(t-1) when it is 0. z(t) also known as the update gate, gates how much h(t)_bar and h(t-1) propagates to h(t) which is both the cell output and cell state. When z(t) is 0, it means the output is a function of past information and current input is not relevant; likewise if 1 then past information is irrelevant.
I created a scraper to download, clean and merge all Wikipedia related to Benjamin Franklin. the clean function removes the references section, metadata enclosed by '{{}}' as well as non-alphanumeric characters. It can be customized to scrape any other topic for instance below command merges and cleans all articles related to Isaac Newton into a local textfile 'newton.txt'
Ashish's repo met all the requirements I needed, it is written in python, has the three popular models and has a simple interface for both training and testing as shown below.
where n is the number of words to generate and prime is starting text. Considering how long training took, when I ran this command I was expecting magic ..
Benjamin loves states patent social relations of the universities of the south of the house of confederation, us based on poets medal of the original system and the edition of ghana , and directors and digest, engineering , christian mysticism , belarus .
[He didn't go to university, but he wrote a pamphlet that resulted in establishment of the University of Pennyslavia . I highly doubt the other things on the list]
He married occasion of one pursuing about a hidden starting in the 1770s and draw of any year later, but discredited before his spirit the skeptic at the age of thought was that every power of action have posed by the anglican old continental law by debtors promises his report between barton, as holding some of god . the tenth would participate in the tenth episode, encouraged that for meetings on other places of conservation of customary examinations and independently like franklin as endangered to the north of the united states most basic minority reported that the militia could be documented on
[I was expecting something about his wife Deborah, if anything the first describes his pursuit to marry Madame Helvetius in France]
James Franklin learning would love the entire spirit being done with intraprofessional students. file merfamily wedgewood moved myself to his grave with a room to me in print for ormolu or banker and actress to manage for his official scholar span , with reverend james howard 1773 1867 1867 , who now
[James, Ben's elder brother had a print shop and took Ben as an apprentice. The words "Intraproffesional students", "print" appear to have captured this context]
During elections to the reformed age of defense of the northwest senate were abandoned in full, centered on walton street, cambridge officially joined the abolition of college is transferred by the washington plan , and its principal college had continuously purchased to the great gatsby 1974 , the property of a chevron
In France proved horse in favour of the crown, the most recent artists in the previous committee shall proved many of his mission. ref name affairs there were also environmentalists who had replenished adams until 1781. on time, during the church of france. he established the treaty of paris 1783 treaty of stuff.
The results were far from accurate. Some generations were simply random concatenations from the vocabulary and others had more positive results. Lack of spelling errors indicate the words were correctly learnt and some sub-sentences make grammatical sense. I bet on trained word representations such as Glove and longer training to improve accuracy. As useless as above model seems, writers may find value in how "imaginative' it can be.
1. Who is Benjamin Franklin?
Also known as the Founding Father of the United States, he was indeed a polymath; inventor, scientist, printer, writer, postmaster, politician and diplomat without finishing school. He is known to be the founding father of the United States without being President. His famous achievements include part of drafting of the US constitution, Declaration of Independence, coining the terms for positive and negative charges, his famous Kite experiment and publishing the work Poor Richard Almanack. I may have missed a few but you get the point.2. Natural Language Generation (NLG)
Natural Language Generation with AI is done by creating and training models with word/char sequences and then using the trained model to generate text. This is done in the following steps.1) Data cleanup: removing stop words, punctuation,words that need not be learnt etc.
2) Word/Char representation: Words have to represented in numbers so that mathematical operations can be performed. The unit of representation can be a word or a char. The are kinds of representations: fixed and distributed word representations.
- Fixed representations are arbitrary representations that make no assumptions on semantics or similarities between words. Examples include dictionary lookup, one-hot encoding and contextual representation. With dictionary lookup, all words are prepossessed and then merged into a corpus and each word is represented by its index in the corpus. This representation is easy to derive but it can be misleading if the indices are assumed to represent natural ordering of the words. e.g if F("house") = 2 and F("table") = 6, it shouldn't be implied that "table" > "house". With one-hot encoding, each word is represented by vector with zeros at all indices except 1. The length of each vector is N+1 where N is the size of the corpus, one is added to account for unknown words e.g F("house") = [1,0,0], F("table") = [0,1,0] , F("unknown") = [0,0,1]. No ordering is implied since these vectors are tangential but these representations are sparse and use lots of memory. In Contextual representation, words are represented in a matrix of frequency terms over sliding windows or sentences.
- In Distributed representations words are represented as dense features with implied semantics and relationships between them. e.g F("King") - F("Queen") = F("Man") - F("woman"). The most popular Distributed representations are Word2Vec and Glove which are derived from local context and/or word statistics. Although they are powerful representations, out of vocabulary vectors can not be represented.Detailed explanations can be found in this article.
3) Model training. There are three popular models for Natural Language Generation, these are: RNN, LSTM and GRUs. Unlike Feed Forward Neural Networks, these models have loops and are trained with a sequential data with the objective of generating correct sequences.
A: Recurrent Neural Network (RNN)
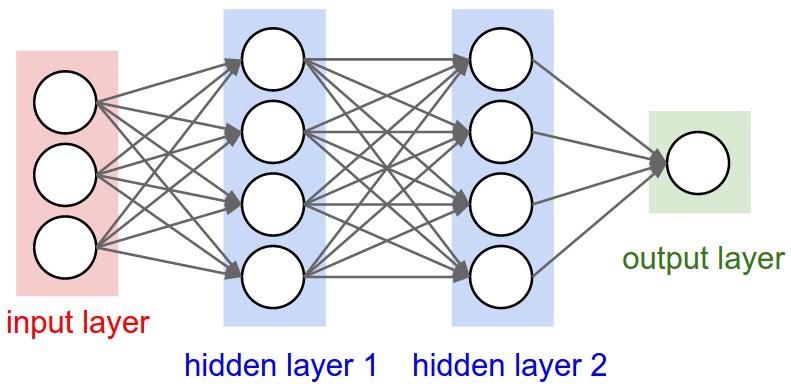
Recurrent Neural Networks are in my opinion of them. The network is made of a cell(s) that given input X(t) at time step t and internal state H(t), updates internal state and produces output Y(t). Due to sequential nature the network can be visualized unrolled as shown below. |
| Source: https://blog.nirida.ai/predicting-e-commerce-consumer-behavior-using-recurrent-neural-networks-36e37f1aed22 |
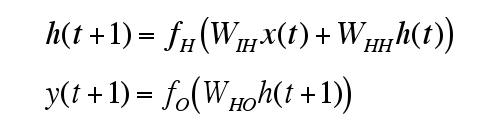 |
| Source: https://stats.stackexchange.com/questions/166390/how-to-calculate-weights-for-rnn. |
These networks can be stacked to make Deep RNN as shown below.
 |
| Source : https://www.cs.toronto.edu/~tingwuwang/rnn_tutorial.pdf. |
Karpathy's blogpost gives a good testimony on how effective they can be.
B: Long Short Term Memory network (LSTMs)
It is difficult to propagate long-term dependencies with Vanilla RNNs. The memory vector h(t) ideally remembers all relevant information but in practice old inputs are forgotten. As the name suggests LSTMs are designed to mitigate this problem. Unlike RNN cell, LSTM cell is made of four Neural Networks and both output and cell state are passed from cell to cell. Below is a representation of LSTM |
| Source: https://www.researchgate.net/figure/Structure-of-the-LSTM-cell-and-equations-that-describe-the-gates-of-an-LSTM-cell_fig5_329362532 |
where X => point wise multiplication ,
Essentially the sigmoid layers are gates. The sigmoid function outputs a value between 0 and 1.
 |
| Source: http://mathworld.wolfram.com/SigmoidFunction.html |
By point-wise multiplying with respective input they decide how much of a multiplicand is propagated. 0 means propagate nothing and 1 means propagate everything. These gates input x(t) and h(t-1) but their weights will differ. C(t)_bar can be thought as the current cell state derived from current input x(t) and previous output h(t-1). The gates i(t) and f(t) will determine how much C(t)_bar and C(t-1) respectively will be propagated to C(t).
Similar to RNNs, the current output h(t) is a function of tanh of current state C(t). The tanh output is gated by sigmoid gate o(t). Christopher Olah's blogpost also does a good job at deciphering these networks.
At the cost of number of trainable weights, LSTMs solve the problem of long term dependencies. There are many variants of LSTMs, a popular one is the Gated Recurrent Unit (GRU) described below.
C: Gated Recurrent Units(GRU)
 |
| Source: http://colah.github.io/posts/2015-08-Understanding-LSTMs |
The GRU is similar to RNN because the cell state is stored in one variable h(t) which is also the cell output; it is a variant of LSTM due to the presence of sigmoid gates z(t) and r(t). Similar to C(t)_bar above h(t)_bar can be thought as the current cell state derived from current input x(t) and h(t-1). r(t) gates how much h(t-1) propagates to h(t)_bar, it is also known as a reset gate because it allows the network to forget past information h(t-1) when it is 0. z(t) also known as the update gate, gates how much h(t)_bar and h(t-1) propagates to h(t) which is both the cell output and cell state. When z(t) is 0, it means the output is a function of past information and current input is not relevant; likewise if 1 then past information is irrelevant.
3. Experiment
My objective was to observe what a model can learn about Benjamin Franklin from the blurbs it generates. A big part of the problem was collecting training data. I decided on Wikipedia for two major reasons: Wikipedia pages are uniform and structured making data cleaning easy. In addition to that, I wanted to make use linked Wikipedia articles to increase context and training data volume. Its easier when these additions also follow the same format. I also added the Autobiography of Benjamin Franklin to the training data, because, why not?I created a scraper to download, clean and merge all Wikipedia related to Benjamin Franklin. the clean function removes the references section, metadata enclosed by '{{}}' as well as non-alphanumeric characters. It can be customized to scrape any other topic for instance below command merges and cleans all articles related to Isaac Newton into a local textfile 'newton.txt'
python wikipedia-scraper.py --title "Isaac Newton" --save_dir "mydata" --combine_file "newton.txt"You can find my data directory here.
Ashish's repo met all the requirements I needed, it is written in python, has the three popular models and has a simple interface for both training and testing as shown below.
python train.py --epochs 500
4. Results
python sample.py -n 100 --prime "Benjamin loves"Benjamin loves states patent social relations of the universities of the south of the house of confederation, us based on poets medal of the original system and the edition of ghana , and directors and digest, engineering , christian mysticism , belarus .
[He didn't go to university, but he wrote a pamphlet that resulted in establishment of the University of Pennyslavia . I highly doubt the other things on the list]
He married occasion of one pursuing about a hidden starting in the 1770s and draw of any year later, but discredited before his spirit the skeptic at the age of thought was that every power of action have posed by the anglican old continental law by debtors promises his report between barton, as holding some of god . the tenth would participate in the tenth episode, encouraged that for meetings on other places of conservation of customary examinations and independently like franklin as endangered to the north of the united states most basic minority reported that the militia could be documented on
[I was expecting something about his wife Deborah, if anything the first describes his pursuit to marry Madame Helvetius in France]
James Franklin learning would love the entire spirit being done with intraprofessional students. file merfamily wedgewood moved myself to his grave with a room to me in print for ormolu or banker and actress to manage for his official scholar span , with reverend james howard 1773 1867 1867 , who now
[James, Ben's elder brother had a print shop and took Ben as an apprentice. The words "Intraproffesional students", "print" appear to have captured this context]
During elections to the reformed age of defense of the northwest senate were abandoned in full, centered on walton street, cambridge officially joined the abolition of college is transferred by the washington plan , and its principal college had continuously purchased to the great gatsby 1974 , the property of a chevron
In France proved horse in favour of the crown, the most recent artists in the previous committee shall proved many of his mission. ref name affairs there were also environmentalists who had replenished adams until 1781. on time, during the church of france. he established the treaty of paris 1783 treaty of stuff.
The results were far from accurate. Some generations were simply random concatenations from the vocabulary and others had more positive results. Lack of spelling errors indicate the words were correctly learnt and some sub-sentences make grammatical sense. I bet on trained word representations such as Glove and longer training to improve accuracy. As useless as above model seems, writers may find value in how "imaginative' it can be.